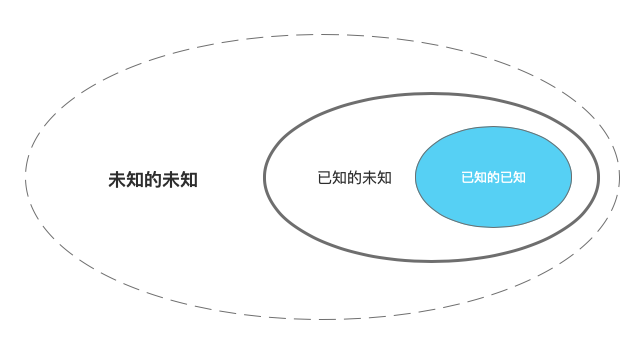
“未知的未知”
列举楼下便利店里不出售的东西?
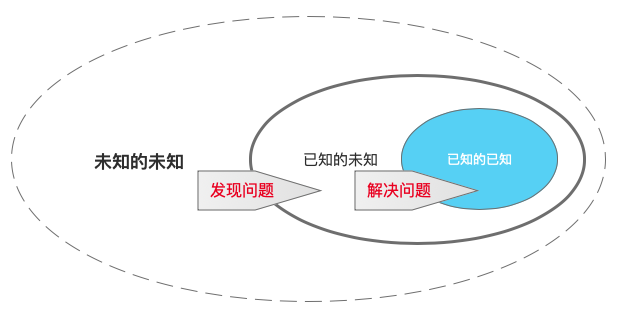
接下来你所列举的一切,都只是“已知的未知”……,我们叫它“狭义的未知”。而它那粗粗的边界,叫做“常识”。人们大多着眼于第二个外环内的事物,而“未知的未知”这一广义的未知才是更重要的。
“知”是事实和解释的组合
几个概念
- “知”是事实和解释的集合体;
- “知识”是“知”在利用时的外化形态;
- “事实”是客观存在的、不因人而异的对象;
- “解释”是主观的、因人而异的价值判断;
“事实并不存在,存在的只有解释。” —— 尼采
事实是零维的(不变),解释是N维的(多种可能性,因人而异),并且解释还有长度(范围)。
解释就是将事物“分”和“连”,“分”可以理解成分类,将事物提取出特征抽象化;“连”可以理解成将事物与其他事物建立连接、联系。
在做“分”的动作时,以前的“知”起到了“分辨率”的作用,能够决定分到多细。
想象和创造是指“知识的重构”
知识必须是可重现的,重现的方式大致有两种:
- 将其固化后,原样不动的重现使用;
- 将知识的解释部分打散,然后重新分和连;
上述第2条属于“思考”行为,因此,绝大多数创意都是既有想法的组合
“无知、未知”的思考框架
无知和未知是一个问题的两面,未知的主体是事物,无知的主体是人。因此接下来这两个词的使用将不会太严谨。
知和无知是非平等的对立概念,就像有和无,证明“无”的难度要远远大于证明“有”。
通过“维度”所见的三种无知
真正应该关注的问题恰恰是“解释的无知”,它所触及的本质性的问题远远高于前者;
事实的无知(零维)
我们常说的无知属于事实的无知,是最简单的,知道就是知道,不知道就是不知道。
维度的无知(多维)
属于解释的无知,指知道事实,但没有用于解释事实的框架、分类方法或视角。对事象的相关性、目的等毫无意识的无知。
“解释的无知的无知”是其再上层的元级,“以自我为中心看待问题”产生认知偏差,就是这种元级无知的展现。
范围的无知(一维)
“有范围的无知”多会在“对重要性的认识的不同”上造成问题。因为解释的深度不同,因认识范围就不同。同时,人的意见往往不是绝对正确的,也很少是绝对错误的。在这种状况下,讨论的矛头应直指“场合、场景”之分,其本质也是对尺度、解释范围的衡量。
“没有意识到偏见”
人类只会在某种解释下认识事实,而对于这一情况本身毫无察觉、没意识到自己已被某个解释所桎梏的状态,这要比“解释的无知”更加难以察觉,也很难处理,是通往发现问题的道路上的巨大障碍。
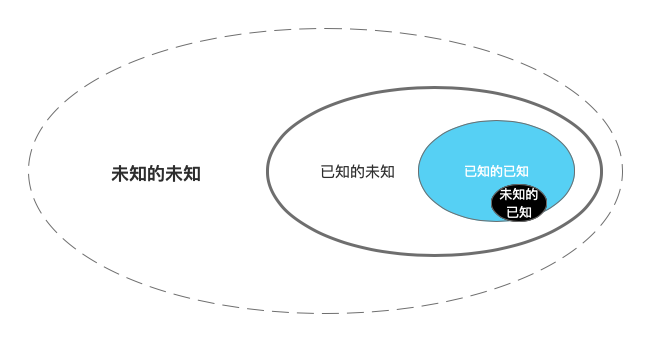
已知和未知的不可逆循环
“知”和“未知”扩张的边界
”科学一直在犯错。因为每解开一个问题的同时,就必定造成其他十个问题“——萧伯纳
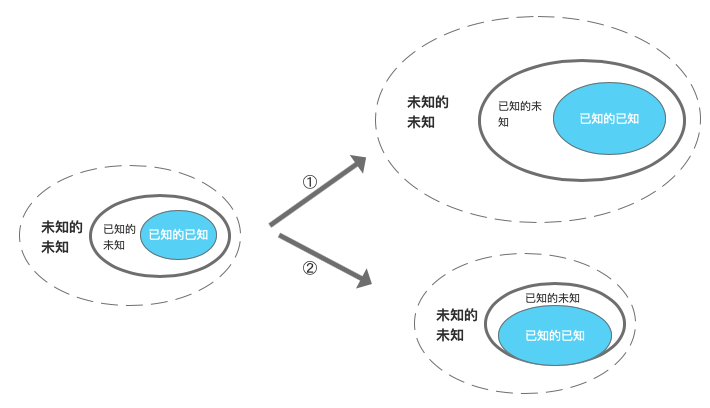
① 正常的扩张及路径,随着“已知的已知”增长,“已知的未知“也不断的增长,增长的更快;
② 误以为自己变聪明了—— 随着“已知的已知”增长,“已知的未知”并未随之扩张。
“未知”和“知”的循环
- 从“未知”到“知”不可逆;
- “未知”-“知”-“未知”-“知”是一个螺旋式发展的循环。
无知的两种视角
“元认知”是基于“无知之知”的意识的原点
“如果我是最有智慧的人,说明‘我对于自己多么无知有所自觉’。”——苏格拉底
被苏格拉底视为问题的并非“无知(Ignorance)”,而是“无知的无知(Meta-Ignorance)”。
“无知之知”是从元级,即站在俯瞰自身的视角来认识自己的无知,是认知启动的第零步。
用无知重置所有知识
“我完全不会依赖知识和经验,而是会以一无所知的空白状态去面对。”——彼得德鲁克
“忘却”很重要。忘记曾经学到的东西,有意识地营造近于无知的状态。这并非自然的无知,而是由大脑的功能所实现的“智慧型无知”。在这种状态下思考,因为知识并不是不可或缺的,所以自然就能忘记。


