设计思路按层次关系划分,数据路径上包括业务建模,概念建模,逻辑建模,物理建模四个层次。
- 业务建模是针对公司或者部门级的业务进行全方面的梳理和分解。
- 概念建模是对业务模型进行抽象出来实体以及实体与实体之间的关系。
- 逻辑模型是对概念模型进行具体的设计,实体的属性,主键,外键等等。
- 物理模型是将逻辑模型具体实施,考虑各种具体的技术实现因素,进行数据仓库体系结构设计,真正实现数据在数据仓库中的存放。
设计思路按层次关系划分,数据路径上包括业务建模,概念建模,逻辑建模,物理建模四个层次。
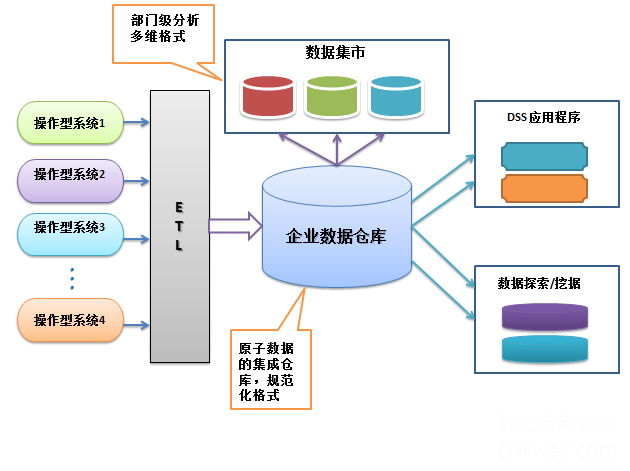
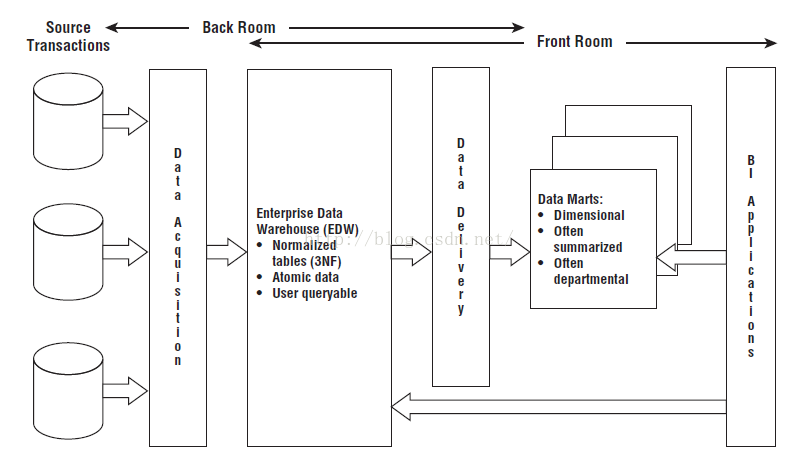
Bill Inmon的经典著作是《数据仓库》-Building the Data Warehouse.
他将数据仓库定义为,一个面向主题的、集成的、随时间变化的、非易变的用于支持管理的决策过程的数据集合。每个主题区域仅仅包含该主题相关的信息。数据仓库应该一次增加一个主题,并且当需要容易地访问多个主题时,应该创建以数据仓库为来源的数据集市。
Inmon模式设计是自顶向下的(top down)瀑布流式开发方法。数据源往往是异构的,主要的数据处理工作集中在对异构数据的清晰、类型检验、值范围检验等规则。以数据源头为导向,首先,探索性的获取尽量符合预期的数据,尝试将数据按照预期划分为不同的表需求。其次,明确数据清洗规则后通过ETL转化到DW层,这里较多UDF开发(User-Defined Function),将数据抽取为实体-关系模型。接着,可以将数据输出到DM层供BI环节使用。
模式:范式建模(第三范式),集线器式建模,一般用于ODS和DW层,不对外开放
重点:数据的清洗工作,从中抽取实体-关系
优点:冗余少,数据模型泛化,精心抽象设计,方便维护
简单地说,1NF就是消除重复元组,并保持列的原子性,具体到数据库设计上就是每个表都要有一个主键来唯一标识一行记录。2NF就是在1NF的基础上消除了部分依赖,即非键属性必须完全依赖于主键。3NF在2NF基础上消除了传递依赖,即非键属性只能完全依赖于主键。一般数据库设计需要满足3NF。
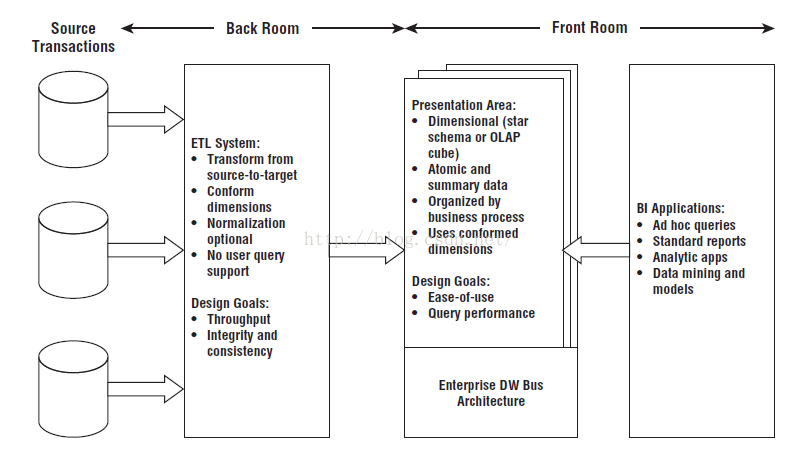
Ralph Kimbal的经典著作是《数据仓库工具箱》-The Data Warehouse Toolkit.
他对数据仓库的定义为,数据仓库仅仅是构成它的数据集市的联合。通过使用“一致的”维,能够共同看到不同数据集市中的信息,这表示它们拥有公共定义的元素。
Kimball模式设计从流程上是自底向上的(bottom up),以最终任务为导向,根据业务需求对源数据进行探索,拆分出不同的表需求;然后通过ETL将数据转化到DM层(维度表+事实表),之后一方面想BI环节输出数据,另一方面向DW层输出数据。
模式:维度建模,总线式建模(星型模型),一般用于DM层
重点:建立事实表和维度表
优点:快速交付、敏捷迭代、对DW层不做过多复杂设计
维度建模允许进行一定的数据冗余来起到减少表间关联和快速查询的作用

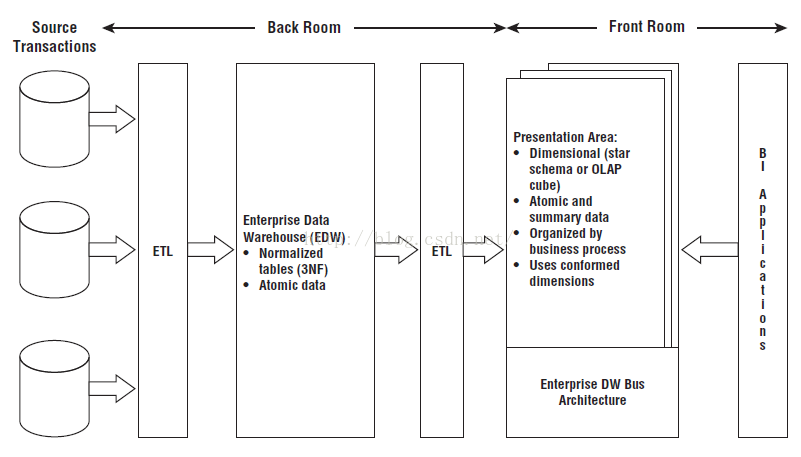
结合了两个模式的特点
# yum install perl-boolean
# yum install postgresql-plperl
# wget http://files.directadmin.com/services/9.0/ExtUtils-MakeMaker-6.31.tar.gz
# wget http://search.cpan.org/CPAN/authors/id/E/EX/EXODIST/Test-Simple-1.302125.tar.gz
# wget http://search.cpan.org/CPAN/authors/id/J/JP/JPEACOCK/version-0.9918.tar.gz
# wget http://www.cpan.org/authors/id/T/TU/TURNSTEP/DBD-Pg-3.5.0.tar.gz
# wget http://search.cpan.org/CPAN/authors/id/T/TI/TIMB/DBI-1.630.tar.gz
# wget http://bucardo.org/downloads/dbix_safe.tar.gz # wget http://bucardo.org/downloads/Bucardo-5.4.1.tar.gz以上perl模块安装步骤
# tar xvf (...)
# cd (...)
# perl Makefile.PL
# make
# make install在系统用户的home目录下创建.bucardorc文件,内容如下:
log_conflict_file = /home/devops/bucardo/log/bucardo_conflict.log
piddir = /home/devops/bucardo/run
reason_file = /home/devops/bucardo/log/bucardo.restart.reason.log
warning_file = /home/devops/bucardo/log/bucardo.warning.log
syslog_facility = LOG_LOCAL
# yum install perl-ExtUtils-MakeMaker# yum install ‘perl(Data::Dumper)’假设基本配置如下:
CONNECT 'libpg connstr' | CONNECT connect_func(...) | argname;CONNECT后面可以直接跟一个libpq的连接字符串,也可跟一个函数,由其返回一个libpq连接串;或跟一个函数参数名,指定连接哪一个数据库。
一个proxy函数中只能出现一条connect语句
CONNECT 'hostaddr=172.16.3.150 dbname=db0 user=digoal port=1921'; CLUSTER 'cluster_name' | CLUSTER connect_func(...) | argname;CLUSTER后面跟一个标识集群名称的字符串,也可以跟一个函数,由其返回一个集群名称;还可跟一个参数名,参数内容为一个集群名称。
RUN ON ALL | ANY | <NR> | partition_func(...);TARGET other_function;可以让后端的函数名与Proxy节点的函数名不一样,如:
<!—hexoPostRenderEscape:
CREATE OR REPLACE FUNCTION get_user_email(i_username text)
RETURNS SETOF text AS $$
CLUSTER ‘cluster_zly’;
RUN ON hashtext(i_username);
TARGET get_customer_email;
$$ LANGUAGE plproxy
proxy节点函数
ddl函数
CREATE OR REPLACE FUNCTION zly.ddlexec(query text)
RETURNS SETOF integer AS
$BODY$
CLUSTER 'cluster_zly';
RUN ON ALL;
$BODY$
LANGUAGE plproxy VOLATILE
COST 100
ROWS 1000;
ALTER FUNCTION zly.ddlexec(text)
OWNER TO postgres;
dml函数(随机insert,不适用update,delete)
CREATE OR REPLACE FUNCTION zly.dmlexec(query text)
RETURNS SETOF integer AS
$BODY$
CLUSTER 'cluster_zly';
RUN ON ANY;
$BODY$
LANGUAGE plproxy VOLATILE
COST 100
ROWS 1000;
ALTER FUNCTION zly.dmlexec(text) OWNER TO postgres;
dql函数(查询)
CREATE OR REPLACE FUNCTION zly.dqlexec(query text)
RETURNS SETOF record AS
$BODY$
CLUSTER 'cluster_zly';
RUN ON ALL;
$BODY$
LANGUAGE plproxy VOLATILE
COST 100
ROWS 1000;
ALTER FUNCTION zly.dqlexec(text) OWNER TO postgres;
data节点函数
ddl函数
CREATE OR REPLACE FUNCTION zly.ddlexec(query text)
RETURNS integer AS
$BODY$
declare
ret integer;
begin
execute query;
return 1;
end;
$BODY$
LANGUAGE 'plpgsql' VOLATILE
COST 100;
dml函数(插入)
CREATE OR REPLACE FUNCTION zly.dmlexec(query text)
RETURNS integer AS
$BODY$
declare
ret integer;
begin
execute query;
return 1;
end;
$BODY$
LANGUAGE 'plpgsql' VOLATILE
COST 100;
dql函数(查询)
CREATE OR REPLACE FUNCTION zly.dqlexec(query text)
RETURNS SETOF record AS
$BODY$
declare
ret record;
begin
for ret in execute query
loop
return next ret;
end loop;
return;
end;
$BODY$
LANGUAGE 'plpgsql' VOLATILE
COST 100
ROWS 1000;
测试
批量建表:
select zly.ddlexec('create table t1(id integer,name varchar(100))');
插入数据:
select zly.dmlexec('insert into t1 values(0,'aaa')');
查询数据数量:
select * from zly.dqlexec('select cast(count(id) as int) as cnt from t1 ') as (cnt int) ;
查询数据内容:
select * from zly.dqlexec('select * from t1') as (id integer, name varchar );