设计思路按层次关系划分,数据路径上包括业务建模,概念建模,逻辑建模,物理建模四个层次。
- 业务建模是针对公司或者部门级的业务进行全方面的梳理和分解。
- 概念建模是对业务模型进行抽象出来实体以及实体与实体之间的关系。
- 逻辑模型是对概念模型进行具体的设计,实体的属性,主键,外键等等。
- 物理模型是将逻辑模型具体实施,考虑各种具体的技术实现因素,进行数据仓库体系结构设计,真正实现数据在数据仓库中的存放。
业务建模——Business Model
首先要与业务部门充分沟通,包括业务的整体逻辑和执行流程,和业务部门的分析需求
业务建模步骤
- 顶层模型:从公司整体业务的角度出发,划分业务模块和各模块之间的交互关系。比如交易模块,财务模块,营销模块和它们之间的关系。
- 业务域:把划分的模块注意进行分解到业务用例。比如营销活动模块中的运营人员配置活动信息,用户购买产品使用优惠券等。
- 业务流程:把业务用例的具体流程分解,每一步的顺序、影响、依赖等。
- 业务环节:把流程每一个环节再标准化(SOP),正常情况和异常情况下的结果都是什么。
概念建模——Concept Model
概念建模主要是在业务模型中抽象出实体和关系(ER),可以在不考虑实体的具体属性。
概念建模步骤
- 从每个业务环节抽象实体
- 抽象实体间的关系,一对一,一对多,多对多。
- 合并汇集所有实体和关系
逻辑建模——Logical Data Model
逻辑建模阶段是最重要的一环,也就是维度建模。涉及到了整个数据仓库所有层次的模型设计,从DW到DM到OLAP。
逻辑建模步骤
- 分析主题域:确定要装载到数据仓库的主题名称,以及各自主题的码键和属性组;主题内的实体,及其容量和更新频率;实体的列的属性等
- 粒度模型的设计:通过粗略估算数据量来确定粒度层次的划分,是单一粒度还是多重粒度(比如1年内的数据是天粒度的,历史记录是月粒度的)
- 数据分割设计:针对某一实体的数据应该是按怎样的方式来分割,一般是按照时间来分割,比如每天的数据放在一个分区里面。
- 元数据模型的建立:在各种转换和汇总的过程中建立好元数据模型能更好的维护和理解数据。
原则
- 粒度性:数据仓库不同的层次具有的粒度是不同的,DW层是数据是原子粒度的数据,比如交易数据原子粒度是订单,记录也包括购买的用户以及商家,DM层的数据是面向主题按一定的维度进行汇总的数据,比如商户集市计算当天出售的订单量。
- 共享性:在数据仓库中,通过抽象和集成,把一些(维度)信息汇总起来,并做全局的一致化,使其在整个数据仓库中处于共享状态,任何用户都可以来使用。比如一致性维度。
- 历史性:针对业务分析的需求,需要从历史信息中获取有用的信息,比如评估客户生命周期价值。
- 一致性:逻辑数据模型必须在设计过程中保持一个统一的业务定义。比如,渠道的定义、团体的分类等,应该在整个企业内部保持一致。将来各种分析应用都使用同样的数据,这些数据应按照预先约定的规则进行刷新,保证同步和一致。
- 扩展性:当有新的需要和改变的时候,逻辑数据模型结构要能够做到可扩展,并能使得对用户透明。
范式建模
一般用于ODS层和DW层,Inmon提出的建模理念
遵循第三范式,而且由于线上数据库一般也采用第三范式,所有对于简单业务可以直接装载。但是遇见如下情况,建议使用范式建模重新组织数据:
- 业务数据库的表没有遵循第三范式;
- 有复杂的字段需要解析(如json);
- 业务维度比较复杂,很难直接关联去除所需要的数据;
维度建模
一般用于DW/DM层,kimball提出的建模理念
三个核心:总线架构、一致性维度、一致性事实
特点
- 易用性。数据仓库的目的是DSS,即决策支持系统(Decision Support System ,简称DSS),既然面向的的是分析用户,那么数据越容易理解,越能受用户欢迎,而维度建模包含具有描述特性的维度表可以让用户很容易理解数据,而不像范式建模,由于太过规范化而导致用户对数据的理解有一定的难度,需要对业务的很深很细的了解。
- 性能高。通过数据的处理,排序和整合,构建出来的维度表,不仅能够让用户很方便的理解数据,使用数据,而且在计算所需要的数据的时候,不需要关联太多的表,从而使得计算的性能很高。
- 扩展性。具有非常好的可扩展性,以便容纳不可预知的新数据源和新的设计决策。可以很方便在不改变模型粒度情况下,增加新的分析维度和事实,不需要重载数据,也不需要为了适应新的改变而重新编码。
维度模型也存在一些缺点,比如数据的一致性很难保证,数据的冗余,大量的未读信息处理等。
星型模型
维度建模的核心是星型模型,以维表为总线,事实表以维表为基础的总线矩阵,意味着建设出来的架构正是总线式架构。
- 星型模型更具有易理解性,毕竟维度模型都是直接挂在事实表,没有额外的关联,所有的维度信息都汇集在维表中了。
- 星型模型性能更高。只需要一次的关联就能获取这一维度的所有描述信息。
- 冗余程度要更高,所有有层次关系的维度,都被设计成扁平化,有一定的冗余。但是维度表的冗余相比事实表毕竟不是一个数量级的。鉴于上面的两点,更多的偏爱于星型模型。
一致性维度(维度表)
What
维度一直是大家所熟知的,但是前面加上了“一致性”之后便成了数据仓库特有的一类维度表,其实一致性维度在表结构和属性都没有本质的区别,有一点的差异是数据仓库的星型模型会使得维度表有一定的冗余。那么一致性体现在哪里呢: 维度共享性。共享性体现在整个平台或整个部门共用维度,而不仅仅只是单纯某个业务单独使用。 一般的维度并没有把共享性作为一个共性的标准。然而在维度建模中,一致性维度将作为重心来做。数据仓库70%的工作量和复杂度是用在构建一致性维度。一致性维度将作用于数据仓库和数据集市甚至是OLAP。
When
一致性维度的构建是先于事实表的构建的,但又不是在构建完成一致性维度之后才开始构建事实表,在构建的过程中肯定会有一定的调整。当在构建事实表的时候如果遇到了比较复杂和困难的问题的时候,也要考虑一致性维度构建的是不是合理。
Where
90%+的维度表是直接从ODS层进行ETL建设成的,一般都是业务的基本描述信息,这一过程是在数据缓冲区来做,输出在数据仓库DW层的最底部。还有一些维度的信息或者属性需要建立在数据集市的基础上,一般是用来做分析的指标或者标签,这个时候需要用集市层的汇总数据来打维度的标签,比如商户的标签。这样的维度信息需要回传到原有的维度表。
How
首先用过对业务过程进行梳理,将业务过程所携带的维度信息整理出来生成总线矩阵。一般情况同属一个价值链的业务过程的维度信息大致相同。然后是针对每个维度逐一审核相关的业务过程,对各个业务过程的维度值进行标准化。之后是对不同的业务的维度信息进行汇总,选择或者生成主键。最后设计维度表,并进行适当的迭代更新。
Why
首先是容易管理,一致性维度不仅规范化,而且大大减少维度表的数量。其次是容易使用,同一主题或者实体的维度表单一,容易获取和使用。所有的事实共享同样的维度,容易进行交叉计算。
类型
- TYPEI(不变)
- 维度属性值持久不变,只有新增和删除
- 属性能够在一定周期(比如一天)内不会变化
- TYPEII(变化)
- 缓慢变化维,部分维度属性可变化,但是变化的频次很低
- 快速变化维,部分维度属性可变化,但是变化的频次很高
- 杂项维度
- 大量不同的零散的维度整合在一起
使用场景
- TYPEI维表适用于大多数这种维度属性经久不变的信息描述,比如日期维度的大多数属性,门店的地址和名称等属性。一般来讲业务上的维度信息都是当天不变的,而且DW用来做数据统计分析是按照一定周期来看的,大多数情况是按天为周期。所以从数据分析的角度上来看,虽然所有维度属性不能能完全不变化,但是只要能获取到当天结束时候的维度信息的快照就可以满足业务上的数据需求。对于生命周期完全不变化的可以建成全量表,其他可以建成快照表。在不明确的情况下优先选择快照表。快照也不会占用太多的空间。
- TYPEII
- 缓慢变化维。在有些情况下,业务上的统计周期相对比较短,就不能按照TYPEI的情况来建设表。此时如果维度变化的频次没有那么快的话,可以建成缓慢变化维度表。缓慢变化维表有几种建设方法,比较常见的一种就是采用effect_from_dt(记录有效起始时间),effect_to_date(记录有效结束时间),current_flag(当前是否有效)等字段的组合。比如营销过程中,一家门店在某几个小时采用的营销手段不同,为了获取当天所有交易的成本,如果没有现成的营销数据的话,完全可以按照交易的时间来匹配当时的营销活动,从而获取营销的成本。
- 快速变化维。情景跟缓慢变化维差不多,唯一的问题在于维度属性变化超级频繁,甚至是秒级分钟级的变化频次,这时候如果依然采用缓慢变化维的构建方式,维表的数据量暴增的很厉害。而且大多数的维度属性没有变化,只有个别的属性变化的厉害而已,导致大量的空间存储的都是不变的信息。这种情况的结局方案是,绝大多数不变的或者变化频次很低的属性集合建成TYPEI或者缓慢变化维表, 而针对变化频次超快的属性单独建立成微型维度表。这两张表没有依赖关系,都是各自挂在事实表上的。
主键和属性
维表主键的选择有两种:自然键,代理键。自然键是具有业务含义的ID,比如身份证号,日期等等,代理键是自动生成的唯一的键。这两种改如何做出选择呢? 如果说业务ID比较有该业务的独特性(不需要跟其他业务集成),或者具有共享性(比如公司级别的,门店ID等等),可以考虑使用自然键,特别的是日期维表直接使用日期来做主键。如果说需要不同的业务维度信息进行整合集成,这种情况比较适合生成代理键来做主键。
物理建模
依照逻辑模型,在数据库中进行建表、索引等。数据仓库。
星型模型:维度表直接跟事实表连接,图型像星星。如区县和地市做为同一维度都在地市表中。
维度预处理,维度会预先进行分类,排序等预处理。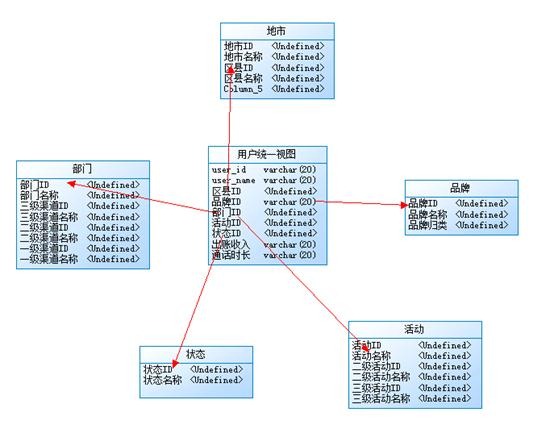
雪花模型:一些维度表不是直接与事实表连接,而是通过维度表中转,图形像雪花。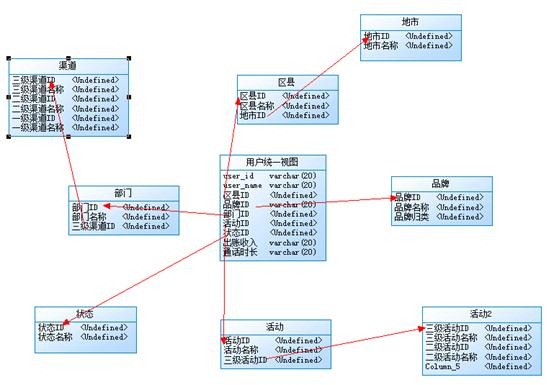
为了满足高性能的需求,可以增加冗余、隐藏表之间的约束等反第三范式操作。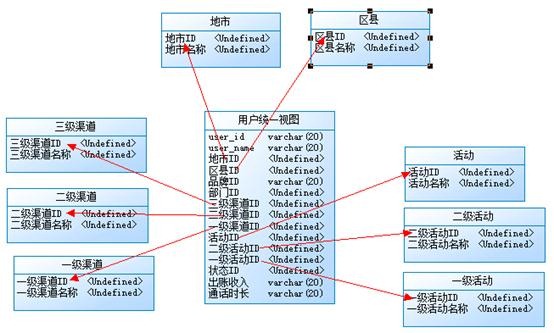
分层设计原则
总的来说分三层:接口层、中间汇总层和应用层。
| 分层 | 子层 | 用途 |
|---|---|---|
| 应用层 | 数据集市 | 第十数据集市、数据挖掘 |
| 应用层 | KPI报表、cognos、主题分析、指标库 | |
| 中间层 | 深度汇总层 | 信息聚合:用户统一视图、3G用户统一视图、固话用户同一视图 业务拓展:用户行为、增值业务、集团业务、国际业务 |
| 轻度汇总层 | 清单汇总、用户属性聚合、费用汇总、集团客户汇总等 | |
| 接口层 | 存储层 | 接口备份、增量转全量、减少I/O |
| 接口层 | 日接口、月接口、增量接口、全量接口 |