建造数据仓库主要包括两个部分的工作:
- 与操作型系统结构的设计
- 数据仓库本身的设计
从操作型数据开始
抽取过程面临的4个问题:集成、性能、抽取过程经历的时基变化、数据压缩
将未经集成的数据载入到数据仓库是一个极端严重的错误,从操作型环境到数据仓库有三种装载工作要做:
- 装载档案数据
- 装载在操作型系统中的现有数据
- 将上次数据仓库刷新以来在操作型环境中不断发生的变化(更新)从操作型环境中装载到数据仓库中
前两种装载工作都是一次性的,并不困难,第三种工作则是常态的,而限制扫描的操作型数据量是设计者面对的主要问题。
共有5种技术可以采用:
- 扫描在操作型环境中哪些被打伤时间戳的数据。但带有时间戳的数据很少,或需要手工加入到操作型环境中。
- 扫描增量文件。但很少应用创建增量文件。
- 对作为事务处理的副产品产生的日志文件或审计文件进行扫描。
- 修改应用程序代码。但很多应用程序的代码陈旧且不易修改。
- 将一个“前”映像文件和一个“后”映像文件进行比较。这是最可怕的选择。
数据/过程模型与体系结构化环境
过程模型是需求驱动的,仅适用于操作型环境。包括功能分解、第零层上下文图、数据流图、结构图、状态转换图、HIPO图、伪代码。
数据模型即可用于操作型环境,又可用于数据仓库环境
数据仓库与数据模型
企业数据模型 -> 操作型数据模型:
- 基本等价
- 加入性能因素
企业数据模型 -> 数据仓库数据模型
- 去掉纯操作型数据
- 关键字中加入时间元素
- 合适之处增加导出数据
- 创建人工关系
- 稳定性分析,根据各个数据属性是否经常变化的特性将这些属性分组(很少改变,不时改变,经常改变)
数据仓库的数据模型
数据建模分为三个层次:
- 高额那个建模(实体关系图,或ERD)
- 中间层建模(数据项集,或DIS)
- 底层建模(物理模型)
中间层数据建模

- 主要数据分组:每个主题域有且仅有一个主要数据分组,包含了对每个主题域只存在一次的属性。
- 二级数据分组:包含每个主题域可以存在多次的数据属性。
- 连接器:标识两个主题域间的数据关系,在ERD层确定的每一个关系在DIS层必须有与其对应的连接器。
- 数据的“类型”:左边的数据分组是超类型,右边的数据分组是子类型。
如: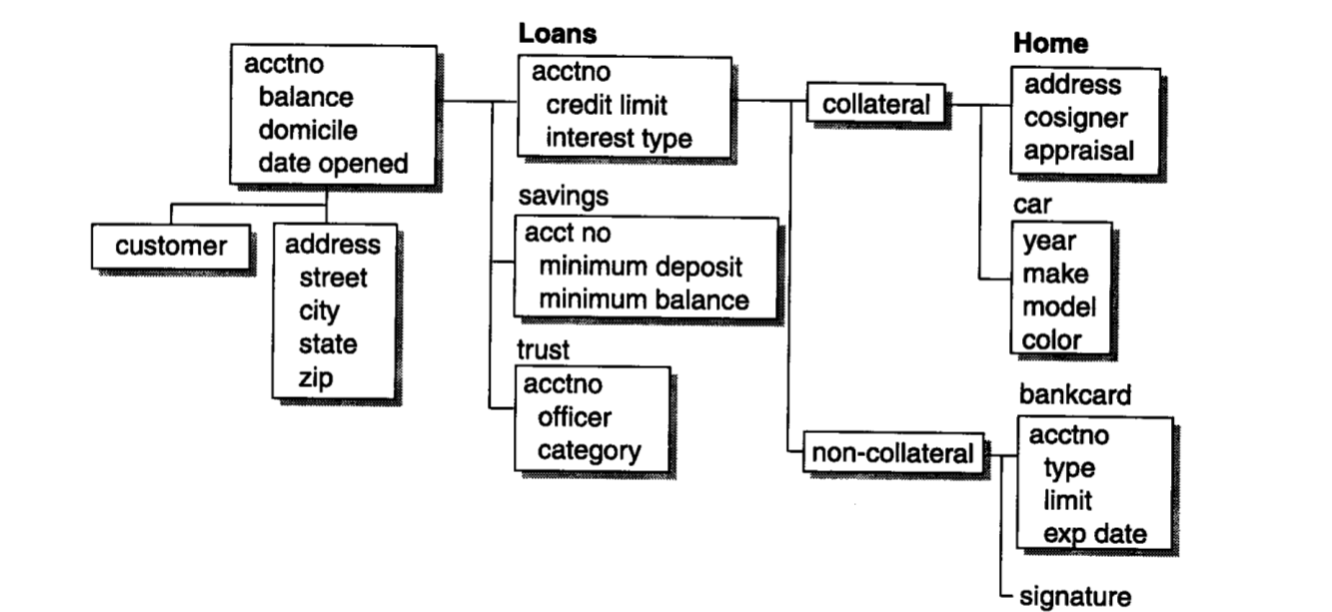
物理数据模型
通过扩展中间层模型,使模型中包含有关键字和物理特性。为了保证执行一次物理IO能返回最大数量的记录,可以采用一些在数据经常需要更新的情况下不能接受的物理设计技术。
数据模型与迭代开发
- 业界成功案例都是迭代的
- 最终用户在第一遍迭代完成前不能清晰的提出需求
- 必须尽快见到成果
- 只有实际结果切实而明确时,管理部门才会做出充分承诺
规范化/反向规范化
主要为了物理模型的设计,减少物理IO,提高性能
- 合并物理表
- 创建数据数组:要求数列中值的数量稳定,数据按顺序访问,数据的创建和修改在统计上非常有规律等条件下。
- 引入冗余数据:(更新慢,访问快,但数据仓库一般不更新)
- 对数据进一步分离:将常用数据和不常用数据分表
- 引入导出数据:即已计算出的数据
元数据
元数据就是关于数据的数据,与指向数据仓库内容的索引相似,处于数据仓库的上层,并且记录数据仓库中对象的位置。
一般记录以下内容:
- 程序员所致的数据结构
- DSS分析员所知的数据结构
- 数据仓库的源数据
- 数据进入数据仓库时进行的转换
- 数据模型
- 数据模型和数据仓库的关系
- 抽取数据的历史记录
数据仓库中的参照(字典)表管理
参照表也需要加入时间元素,否则可能与数据对应出错:
- 每隔一段时间对参照表生成一次快照。但逻辑上不完备,即如果在一个周期内发生的多次更改无法记录。
- 某个时间点生成一个快照,之后收集记录所有对参照表的活动。逻辑完备,但复杂繁重。
这是两种极端方案,可以中和方案。
数据周期——时间间隔
数据周期是指从操作型环境中的数据发生改变起,到这个变化反映到数据仓库中所用的时间。